数组(Arrays)
数组是一系列相同类型的元素的集合,在内存中连续存储.
可以通过唯一标识符给它们添加索引来引用这些元素。
例如,5个int类型的值可以声明为一个数组,而不必声明5个不同的变量
(每个变量都有自己的标识符)。相反,使用数组,5个int值存储在连续的内存位置,
并且可以使用相同的标识符和相应的索引访问每个int数。
例如,包含5个整数值的int类型数组foo可以表示为:

其中每个空格代表数组的一个元素。在本例中,这些是int类型的值。这些元素的编号从0到4,第一个是0,
最后一个是4;在c++中,数组中的第一个元素总是用0(而不是1)进行编号,不管它的长度如何。
与常规变量一样,数组在使用前必须声明。c++中一个典型的数组声明是:
type name [elements];
其中type是有效的类型(如int, float…),name是有效的标识符,elements字段
(总是用方括号[]括起来)根据元素的数量指定数组的长度。
因此,foo数组有5个int类型的元素,可以声明为:
注意:方括号[]内的字段表示数组中的元素数量,必须是常量表达式,
因为数组是静态内存块,其大小必须在程序运行前编译时确定。
☞ 初始化数组
默认情况下,局部作用域的常规数组(例如,在函数中声明的数组)是不初始化的。
这意味着它的元素没有一个被设置值;元素的内容在声明数组时是未确定的。
但是数组中的元素可以在声明时显式地初始化为特定的值,
方法是将这些初始值括在大括号{}中。例如:
int foo [5] = { 16, 2, 77, 40, 12071 };
|
这个语句声明了一个可以这样表示的数组:

大括号{}之间的值个数不能大于数组中的元素个数。例如,在上面的例子中,
foo声明有5个元素(用方括号括起来的数字[]来指定),
而大括号{}正好包含5个值,每个元素一个。如果声明的元素数量大于实际的数量,
则将其余元素设置为它们的默认值(对于基本类型,这意味着它们被填充为零)。例如:
int bar [5] = { 10, 20, 30 };
|
将像这样创建一个数组:

初始化甚至可以没有值,只有大括号:
这将创建一个由5个int值组成的数组,每个int值初始化为0:

当为数组提供值的初始化方式时,c++允许将方括号[]保留为空。
在这种情况下,编译器会自动设定数组的大小与大括号{}之间包含的值的数量相匹配:
int foo [] = { 16, 2, 77, 40, 12071 };
|
在这个声明之后,数组foo将是5个int 类型长度,因为我们已经提供了5个初始化值。
最后,c++的发展导致对数组也采用了通用初始化。因此,在声明和初始化式之间不再需要等号。
这两个语句是等价的:
int foo[] = { 10, 20, 30 };
int foo[] { 10, 20, 30 };
|
静态数组和那些直接在命名空间(任何函数之外)中声明的数组总是初始化的。
如果没有指定显式初始化式,则所有元素都默认初始化(对于基本类型使用零)。
☞ 访问数组的值
数组中任何元素的值都可以像访问相同类型的常规变量的值一样访问。它的语法是:
name[index]
在前面的例子中,foo有5个元素,每个元素都是int类型的,可以用来引用每个元素的名字如下:

例如,下面的语句将值75存储在foo的第三个元素中:
例如,下面的代码将foo的第三个元素的值复制到一个名为x的变量中:
因此,表达式foo[2]本身就是一个int类型的变量。
注意foo的第三个元素被指定为foo[2],因为第一个元素是foo[0],第二个元素是foo[1],
因此第三个元素是foo[2]。出于同样的原因,它的最后一个元素是foo[4]。
因此,如果我们写foo[5],我们将访问foo的第六个元素,那么实际上超过了数组的大小。
在c++中,超出数组索引的有效范围在语法上是正确的。但是会产生问题,
因为访问超出范围的元素不会在编译时导致错误,但会在运行时导致错误。
允许这样做的原因将在后面介绍指针时看到。
此时,能够清楚地区分与数组相关的两种方括号[]用法非常重要。它们执行两个不同的任务:
一个是在声明数组时指定数组的大小;另一种方法是在访问具体数组元素时指定索引。
不要混淆数组的这两种方括号[]的用法。
int foo[5]; // declaration of a new array
foo[2] = 75; // access to an element of the array.
|
主要的区别是,声明数组的方括号之前有元素的类型,而访问的方括号之前没有。
其他一些有效的数组操作:
foo[0] = a;
foo[a] = 75;
b = foo [a+2];
foo[foo[a]] = foo[2] + 5;
|
例如:
// arrays example
#include <iostream>
using namespace std;
int foo [] = {16, 2, 77, 40, 12071};
int n, result=0;
int main ()
{
for ( n=0 ; n<5 ; ++n )
{
result += foo[n];
}
cout << result;
return 0;
}
|
12206
|
☞ 多维数组
多维数组可以被描述为“数组中的数组”。例如,可以将二维数组想象成由元素组成的二维表,
所有元素都具有相同的统一数据类型。

Jimmy表示一个 3 行 5 列 int 类型元素的二维数组。c++的语法是:
例如,在一个表达式中垂直引用第二个元素和水平引用第四个元素的方法是:
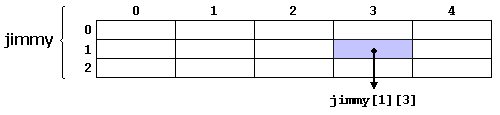
记住数组下标总是以零开始!
多维数组不限于两个索引(即两个维度)。它们可以包含所需的任意数量的索引。
但是要注意:数组所需的内存量随着每个维度呈指数级增长。例如:
char century [100][365][24][60][60];
|
每秒声明这个数组的一个元素需要一个世纪,相当于30亿个char.
所以这个声明会消耗超过 3 GB 的内存!
最后,多维数组只是程序员的抽象,
因为通过将其索引相乘,可以用简单的数组实现相同的结果:
int jimmy [3][5]; // is equivalent to
int jimmy [15]; // (3 * 5 = 15)
|
唯一不同的是,对于多维数组,编译器会自动记住每个虚拟维度的深度。
下面两段代码产生了完全相同的结果,但是其中一段使用了二维数组,
而另一段使用了简单数组:
| 多维数组 |
伪多维数组 |
#define WIDTH 5
#define HEIGHT 3
int jimmy [HEIGHT][WIDTH];
int n,m;
int main ()
{
for (n=0; n<HEIGHT; n++)
for (m=0; m<WIDTH; m++)
{
jimmy[n][m]=(n+1)*(m+1);
}
}
|
#define WIDTH 5
#define HEIGHT 3
int jimmy [HEIGHT * WIDTH];
int n,m;
int main ()
{
for (n=0; n<HEIGHT; n++)
for (m=0; m<WIDTH; m++)
{
jimmy[n*WIDTH+m]=(n+1)*(m+1);
}
}
|
上面的两个代码片段都不会在屏幕上产生任何输出,但都以以下方式在内存给jimmy赋值:

请注意,代码使用已定义的常量来表示宽度和高度,而不是直接使用它们的数值。
这使代码具有更好的可读性,并允许在一个地方很容易地对代码进行更改。
☞ 数组做参数
在某些情况下,可能需要将数组作为参数传递给函数。在c++中,
不可能将数组表示的整个内存块直接作为参数传递给函数。但可以通过它的地址传递。
在实践中,这几乎有相同的效果,它是一个更快和更有效的操作。要接受数组作为函数的形参,
可以将形参声明为数组类型,但使用空方括号,省略数组的实际大小。例如:
void procedure (int arg[]
|
这个函数接受一个名为arg的“int数组”类型的形参。传递给这个函数的数组的声明是:
这样作为一个调用就足够了:
这里有一个完整的例子:
// arrays as parameters
#include <iostream>
using namespace std;
void printarray (int arg[], int length) {
for (int n=0; n<length; ++n)
cout << arg[n] << ' ';
cout << '\n';
}
int main ()
{
int firstarray[] = {5, 10, 15};
int secondarray[] = {2, 4, 6, 8, 10};
printarray (firstarray,3);
printarray (secondarray,5);
}
|
5 10 15
2 4 6 8 10
|
在上面的代码中,第一个形参(int arg[])接受任何长度的元素为int类型的数组。
因此,我们包含了第二个形参,它告诉函数第一个形参传递给它的数组的长度。
这样我们使用for循环遍历(迭代)数组的时候,就可以确定数组的大小了.
在函数声明中,也可以包含多维数组。三维数组参数的格式为:
base_type[][depth][depth]
例如,一个以多维数组作为参数的函数可以是:
void procedure (int myarray[][3][4])
|
注意,第一个方括号[]是空的,而后面的方括号为它们各自的尺寸指定了大小。
这对于编译器能够确定每个维度的深度是必要的。
☞ 库数组
上面解释的数组是作为一种语言特性直接实现的,它继承自C语言。它们是一个很棒的特性,
但是由于限制了它的复制,并且很容易退化为指针,它们可能会受到过度优化的影响。
为了克服语言内置数组的某些问题,c++提供了另一种数组类型作为标准容器。
它是定义在头文件<array>中的类型模板(实际上是类模板)。
容器是一个库特性,不属于本教程的范围,因此这里将不详细解释该类。
我只想说,他们以类似的方式操作内置数组,但是他们允许被复制
(实际上一个昂贵的操作,复制整块的内存,因此小心使用)和
只有(通过其成员数据)明确指定的时候才衰变为指针。
就像下面例子,这是使用本章描述的语言内置数组和库中的容器的同一个例子的两个版本:
| 内置数组 |
容器库数组 |
#include <iostream>
using namespace std;
int main()
{
int myarray[3] = {10,20,30};
for (int i=0; i<3; ++i)
++myarray[i];
for (int elem : myarray)
cout << elem << '\n';
}
|
#include <iostream>
#include <array>
using namespace std;
int main()
{
array<int,3> myarray {10,20,30};
for (int i=0; i<myarray.size(); ++i)
++myarray[i];
for (int elem : myarray)
cout << elem << '\n';
}
|
如您所见,这两种数组使用相同的语法来访问其元素:myarray[i]。除此之外,
主要的区别在于数组的声明,以及库数组的附加头文件。请注意访问库数组的大小非常方便。
